
Summarize this post with:
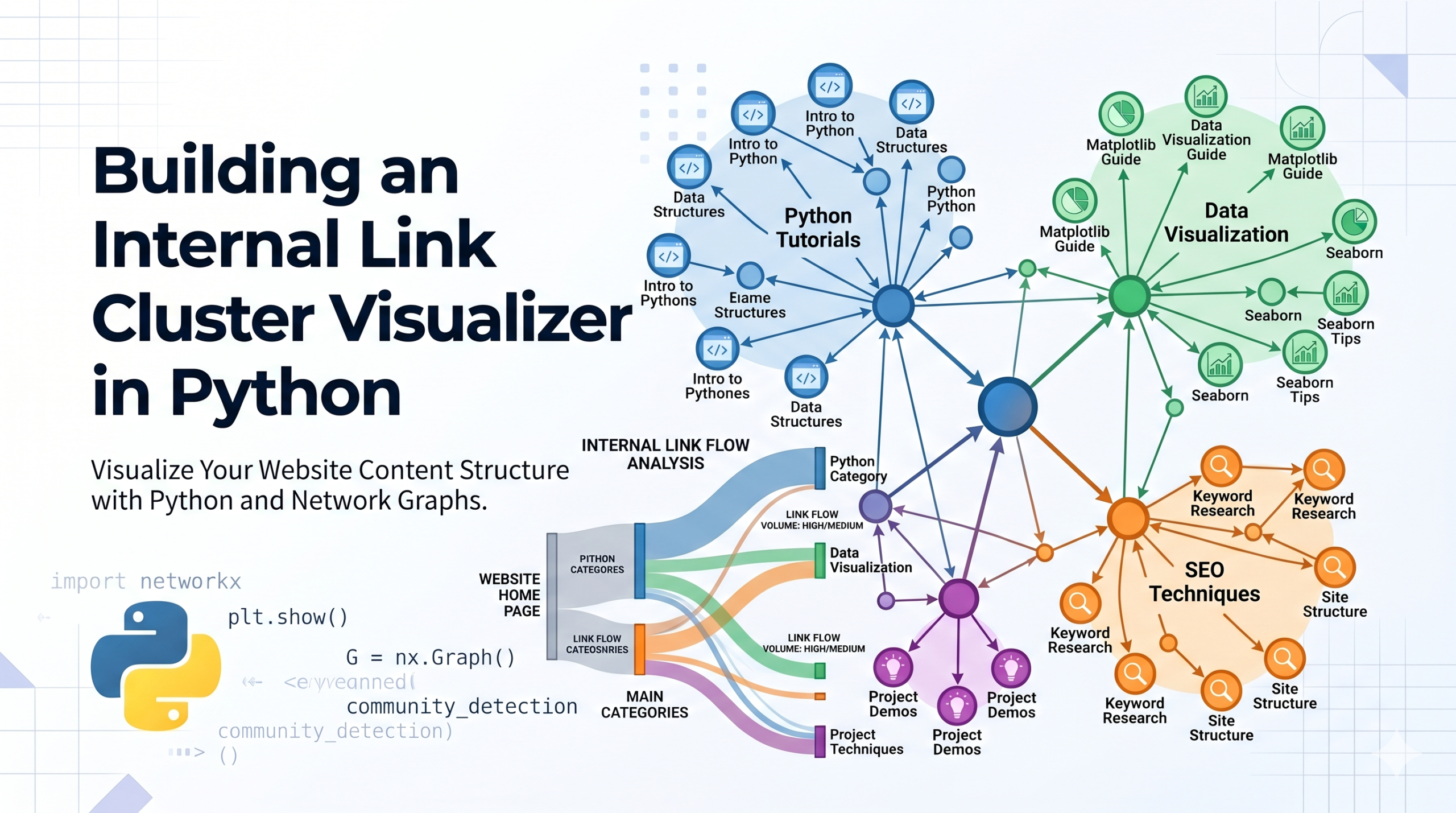
I built a Python Streamlit app that visualizes Internal Link clusters via page type regex so that you can visualize link flow amongst content groups.
Let’s see how the outcome looks like

How it works?
I will share the Python Script also, but UI wise, how it works, let’s break that down.
You have to provide page regex & assign cluster name & then generate the sankey visualization
Let’s see that view of Streamlit

I did this exercise with Screaming Frog crawl of Gymshark website
Now here is the full Python Script that you can use
#!/usr/bin/env python3
"""
Regex-Based Internal Linking Sankey Visualizer (Streamlit App)
Upload an internal linking CSV, define URL-contains rules to cluster URLs,
and visualize link flow between clusters as an interactive Sankey diagram.
Download the Sankey as a self-contained HTML file.
Usage:
streamlit run "sitemap_based-inlinks-sankey - Copy.py"
"""
import re
import csv
import json
from collections import defaultdict
from io import StringIO
import streamlit as st
# ─────────────────────────────────────────────────────────────────────
# SESSION STATE DEFAULTS
# ─────────────────────────────────────────────────────────────────────
if "rules" not in st.session_state:
st.session_state.rules = [
{"pattern": "", "cluster": ""},
]
if "sankey_html" not in st.session_state:
st.session_state.sankey_html = None
UNCLUSTERED_LABEL = "Unclustered"
# ─────────────────────────────────────────────────────────────────────
# URL CLASSIFICATION
# ─────────────────────────────────────────────────────────────────────
def compile_rules(rules: list[dict]) -> list[tuple[re.Pattern, str]]:
"""Compile user-defined rules into (regex, cluster_name) pairs."""
compiled = []
for r in rules:
pattern = r.get("pattern", "").strip()
cluster = r.get("cluster", "").strip()
if not pattern or not cluster:
continue
try:
compiled.append((re.compile(pattern, re.IGNORECASE), cluster))
except re.error:
st.warning(f"Invalid regex pattern: `{pattern}` — skipped.")
return compiled
def classify_url(url: str, compiled_rules: list[tuple[re.Pattern, str]]) -> str:
"""Return the cluster name for a URL based on the first matching rule."""
for regex, cluster in compiled_rules:
if regex.search(url):
return cluster
return UNCLUSTERED_LABEL
def normalize_url(raw: str) -> str:
if not raw:
return ""
url = raw.strip().rstrip("/")
if "#" in url:
url = url.split("#")[0]
return url
# ─────────────────────────────────────────────────────────────────────
# CSV PROCESSING
# ─────────────────────────────────────────────────────────────────────
def process_csv(
file_content: str,
source_col: str,
target_col: str,
compiled_rules: list[tuple[re.Pattern, str]],
exclude_unclustered: bool,
delimiter: str = ",",
) -> tuple[dict[tuple[str, str], int], dict]:
"""Stream-read the CSV and aggregate link counts between clusters."""
reader = csv.DictReader(StringIO(file_content), delimiter=delimiter)
flow: dict[tuple[str, str], int] = defaultdict(int)
cluster_url_counts: dict[str, int] = defaultdict(int)
total_rows = 0
skipped_empty = 0
skipped_unclustered = 0
counted = 0
for row in reader:
total_rows += 1
raw_src = (row.get(source_col, "") or "").strip()
raw_tgt = (row.get(target_col, "") or "").strip()
if not raw_src or not raw_tgt:
skipped_empty += 1
continue
src_cluster = classify_url(raw_src, compiled_rules)
tgt_cluster = classify_url(raw_tgt, compiled_rules)
cluster_url_counts[src_cluster] += 1
cluster_url_counts[tgt_cluster] += 1
if exclude_unclustered and (
src_cluster == UNCLUSTERED_LABEL or tgt_cluster == UNCLUSTERED_LABEL
):
skipped_unclustered += 1
continue
flow[(src_cluster, tgt_cluster)] += 1
counted += 1
stats = {
"total_rows": total_rows,
"skipped_empty": skipped_empty,
"skipped_unclustered": skipped_unclustered,
"counted": counted,
"cluster_url_counts": dict(cluster_url_counts),
}
return dict(flow), stats
# ─────────────────────────────────────────────────────────────────────
# SANKEY DATA PREPARATION
# ─────────────────────────────────────────────────────────────────────
def prepare_sankey_data(
flow: dict[tuple[str, str], int], min_links: int = 0
) -> dict:
node_set: set[str] = set()
for (src, tgt), count in flow.items():
if count <= min_links:
continue
node_set.add(src)
node_set.add(tgt)
sorted_nodes = sorted(node_set)
nodes = []
node_index: dict[str, int] = {}
for name in sorted_nodes:
node_index[name] = len(nodes)
nodes.append({"id": name, "label": name})
links = []
for (src, tgt), count in flow.items():
if count <= min_links:
continue
if src in node_index and tgt in node_index:
links.append(
{
"source": node_index[src],
"target": node_index[tgt],
"value": count,
"sourceLabel": src,
"targetLabel": tgt,
}
)
links.sort(key=lambda x: x["value"], reverse=True)
return {"nodes": nodes, "links": links}
# ─────────────────────────────────────────────────────────────────────
# HTML GENERATION
# ─────────────────────────────────────────────────────────────────────
def generate_html(sankey_data: dict) -> str:
data_json = json.dumps(sankey_data, indent=None)
html = f"""<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Internal Linking — Cluster Sankey</title><style>:root {{
--bg: #0a0b10;
--surface: #111318;
--border: #1e2230;
--text: #e2e4e9;
--text-dim: #6b7084;
--accent: #6c72cb;
--accent2: #cb69c1;
}}
* {{ margin:0; padding:0; box-sizing:border-box; }}
html, body {{
font-family: 'DM Sans', sans-serif;
background: var(--bg);
color: var(--text);
height: 100vh;
overflow: hidden;
}}
body::after {{
content: '';
position: fixed; inset: 0;
background: url("data:image/svg+xml,%3Csvg viewBox='0 0 256 256' xmlns='http://www.w3.org/2000/svg'%3E%3Cfilter id='n'%3E%3CfeTurbulence type='fractalNoise' baseFrequency='0.85' numOctaves='4' stitchTiles='stitch'/%3E%3C/filter%3E%3Crect width='100%25' height='100%25' filter='url(%23n)' opacity='0.025'/%3E%3C/svg%3E");
pointer-events: none;
z-index: 9999;
}}
.layout {{
display: grid;
grid-template-rows: auto auto 1fr;
height: 100vh;
}}
.header {{
padding: 20px 32px 8px;
display: flex;
align-items: baseline;
gap: 24px;
}}
.header h1 {{
font-size: 22px;
font-weight: 700;
letter-spacing: -0.5px;
background: linear-gradient(135deg, var(--accent), var(--accent2));
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
white-space: nowrap;
}}
.stats {{
display: flex;
gap: 20px;
}}
.stat {{
display: flex;
align-items: baseline;
gap: 6px;
}}
.stat .num {{
font-family: 'JetBrains Mono', monospace;
font-size: 16px;
font-weight: 700;
color: var(--accent);
}}
.stat .lbl {{
font-size: 11px;
color: var(--text-dim);
text-transform: uppercase;
letter-spacing: 0.5px;
}}
.controls {{
display: flex;
gap: 14px;
align-items: center;
padding: 8px 32px 12px;
flex-wrap: wrap;
}}
.controls label {{
font-size: 12px;
color: var(--text-dim);
font-weight: 500;
}}
.controls input[type=range] {{
width: 160px;
accent-color: var(--accent);
}}
.controls .val {{
font-family: 'JetBrains Mono', monospace;
font-size: 12px;
color: var(--accent);
min-width: 50px;
}}
.controls button {{
background: var(--surface);
border: 1px solid var(--border);
color: var(--text);
padding: 5px 14px;
border-radius: 6px;
cursor: pointer;
font-size: 12px;
font-family: inherit;
transition: border-color .2s;
}}
.controls button:hover {{ border-color: var(--accent); }}
.search-box {{
background: var(--surface);
border: 1px solid var(--border);
color: var(--text);
padding: 5px 12px;
border-radius: 6px;
font-size: 12px;
font-family: inherit;
width: 180px;
outline: none;
transition: border-color .2s;
}}
.search-box:focus {{ border-color: var(--accent); }}
.chart-area {{
position: relative;
overflow: hidden;
}}
.chart-area svg {{
display: block;
width: 100%;
height: 100%;
}}
.tooltip {{
position: fixed;
pointer-events: none;
background: #15171f;
border: 1px solid var(--border);
border-radius: 8px;
padding: 10px 14px;
font-size: 13px;
color: var(--text);
box-shadow: 0 12px 40px rgba(0,0,0,.5);
z-index: 1000;
opacity: 0;
transition: opacity .12s;
max-width: 320px;
}}
.tooltip.show {{ opacity: 1; }}
.tooltip .tt-from {{ color: var(--accent); font-weight: 700; }}
.tooltip .tt-to {{ color: var(--accent2); font-weight: 700; }}
.tooltip .tt-val {{
font-family: 'JetBrains Mono', monospace;
color: #fff;
font-size: 15px;
margin-top: 4px;
}}
.tooltip .tt-arrow {{ color: var(--text-dim); }}</style></head>
<body>
<div class="layout">
<div class="header">
<h1>Cluster Link Flow</h1>
<div class="stats" id="stats"></div>
</div>
<div class="controls">
<label>Min links</label>
<input type="range" id="minSlider" min="0" max="100" value="0">
<span class="val" id="minVal">0</span>
<input class="search-box" id="search" placeholder="Filter clusters…">
<button id="toggleSelf">Hide self-links</button>
<button id="resetBtn">Reset</button>
</div>
<div class="chart-area" id="chartArea">
<svg id="chord"></svg>
</div>
</div>
<div class="tooltip" id="tooltip"></div> <script>const RAW = {data_json};
let hideSelf = false;
let minLinks = 0;
let searchTerm = '';
let highlightNode = -1;
const PALETTE = [
'#6c72cb','#cb69c1','#41b3a3','#e8a838','#e85d75',
'#4a90d9','#85d94a','#d94a90','#4ad9c5','#d9b84a',
'#8b5cf6','#f59e0b','#10b981','#ef4444','#3b82f6',
'#ec4899','#14b8a6','#f97316','#a855f7','#06b6d4',
'#84cc16','#f43f5e','#0ea5e9','#d946ef','#22d3ee',
];
function getColor(i) {{ return PALETTE[i % PALETTE.length]; }}
function render() {{
let links = RAW.links.filter(l => l.value > minLinks);
if (hideSelf) links = links.filter(l => l.source !== l.target);
const activeIdx = new Set();
links.forEach(l => {{ activeIdx.add(l.source); activeIdx.add(l.target); }});
if (searchTerm) {{
const q = searchTerm.toLowerCase();
const matchIdx = new Set();
RAW.nodes.forEach((n, i) => {{
if (n.label.toLowerCase().includes(q)) matchIdx.add(i);
}});
links = links.filter(l => matchIdx.has(l.source) || matchIdx.has(l.target));
activeIdx.clear();
links.forEach(l => {{ activeIdx.add(l.source); activeIdx.add(l.target); }});
}}
const totalLinks = links.reduce((s, l) => s + l.value, 0);
document.getElementById('stats').innerHTML = `
<div class="stat"><span class="num">${{totalLinks.toLocaleString()}}</span><span class="lbl">links</span></div>
<div class="stat"><span class="num">${{activeIdx.size}}</span><span class="lbl">clusters</span></div>
<div class="stat"><span class="num">${{links.length}}</span><span class="lbl">flows</span></div>
`;
const nodeTotals = {{}};
links.forEach(l => {{
nodeTotals[l.source] = (nodeTotals[l.source] || 0) + l.value;
nodeTotals[l.target] = (nodeTotals[l.target] || 0) + l.value;
}});
const activeNodes = [...activeIdx]
.map(i => ({{ idx: i, label: RAW.nodes[i].label, total: nodeTotals[i] || 0 }}))
.sort((a, b) => b.total - a.total);
const N = activeNodes.length;
if (N === 0) {{
document.getElementById('chord').innerHTML = '<text x="50%" y="50%" text-anchor="middle" fill="#6b7084" font-size="16">No flows to display</text>';
return;
}}
const area = document.getElementById('chartArea');
const W = area.clientWidth;
const H = area.clientHeight;
const SIZE = Math.min(W, H);
const cx = W / 2;
const cy = H / 2;
const outerR = SIZE * 0.36;
const innerR = outerR - Math.max(18, SIZE * 0.04);
const labelR = outerR + 18;
const totalVal = activeNodes.reduce((s, n) => s + n.total, 0) || 1;
const gapAngle = Math.PI * 2 * 0.012;
const totalGap = gapAngle * N;
const availAngle = Math.PI * 2 - totalGap;
const minArcSpan = Math.PI * 2 * 0.015;
const rawSpans = activeNodes.map(n => (n.total / totalVal) * availAngle);
let deficit = 0;
const spans = rawSpans.map(s => {{
if (s < minArcSpan) {{ deficit += minArcSpan - s; return minArcSpan; }}
return s;
}});
if (deficit > 0) {{
const largeTotal = spans.filter(s => s > minArcSpan).reduce((a, b) => a + b, 0);
if (largeTotal > 0) {{
for (let i = 0; i < spans.length; i++) {{
if (spans[i] > minArcSpan) spans[i] -= (spans[i] / largeTotal) * deficit;
}}
}}
}}
const arcs = [];
let angle = -Math.PI / 2;
activeNodes.forEach((n, i) => {{
const span = spans[i];
arcs.push({{
idx: n.idx,
label: n.label,
total: n.total,
startAngle: angle,
endAngle: angle + span,
midAngle: angle + span / 2,
color: getColor(i),
}});
angle += span + gapAngle;
}});
const arcMap = {{}};
arcs.forEach((a, i) => {{ arcMap[a.idx] = i; }});
const arcOffsets = arcs.map(() => 0);
function arcPath(startA, endA, r1, r2) {{
const x1 = cx + Math.cos(startA) * r1, y1 = cy + Math.sin(startA) * r1;
const x2 = cx + Math.cos(endA) * r1, y2 = cy + Math.sin(endA) * r1;
const x3 = cx + Math.cos(endA) * r2, y3 = cy + Math.sin(endA) * r2;
const x4 = cx + Math.cos(startA) * r2, y4 = cy + Math.sin(startA) * r2;
const large = (endA - startA) > Math.PI ? 1 : 0;
return `M${{x1}},${{y1}} A${{r1}},${{r1}} 0 ${{large}} 1 ${{x2}},${{y2}} L${{x3}},${{y3}} A${{r2}},${{r2}} 0 ${{large}} 0 ${{x4}},${{y4}} Z`;
}}
let svg = `<svg viewBox="0 0 ${{W}} ${{H}}" xmlns="http://www.w3.org/2000/svg">`;
svg += `<defs>
<radialGradient id="glow" cx="50%" cy="50%" r="50%">
<stop offset="60%" stop-color="transparent"/>
<stop offset="100%" stop-color="rgba(108,114,203,0.04)"/>
</radialGradient>
</defs>
<circle cx="${{cx}}" cy="${{cy}}" r="${{outerR + 60}}" fill="url(#glow)"/>`;
const flowLookup = {{}};
links.forEach(l => {{ flowLookup[l.source + '::' + l.target] = l.value; }});
const sortedLinks = [...links].sort((a, b) => a.value - b.value);
sortedLinks.forEach(l => {{
const si = arcMap[l.source];
const ti = arcMap[l.target];
if (si === undefined || ti === undefined) return;
const sa = arcs[si], ta = arcs[ti];
const sFrac = l.value / totalVal * availAngle;
const tFrac = l.value / totalVal * availAngle;
const s1 = sa.startAngle + arcOffsets[si];
const s2 = s1 + sFrac;
arcOffsets[si] += sFrac;
const t1 = ta.startAngle + arcOffsets[ti];
const t2 = t1 + tFrac;
arcOffsets[ti] += tFrac;
const sx1 = cx + Math.cos(s1) * innerR, sy1 = cy + Math.sin(s1) * innerR;
const sx2 = cx + Math.cos(s2) * innerR, sy2 = cy + Math.sin(s2) * innerR;
const tx1 = cx + Math.cos(t1) * innerR, ty1 = cy + Math.sin(t1) * innerR;
const tx2 = cx + Math.cos(t2) * innerR, ty2 = cy + Math.sin(t2) * innerR;
const sLarge = (s2 - s1) > Math.PI ? 1 : 0;
const tLarge = (t2 - t1) > Math.PI ? 1 : 0;
const chordD = `M${{sx1}},${{sy1}} A${{innerR}},${{innerR}} 0 ${{sLarge}} 1 ${{sx2}},${{sy2}} Q${{cx}},${{cy}} ${{tx1}},${{ty1}} A${{innerR}},${{innerR}} 0 ${{tLarge}} 1 ${{tx2}},${{ty2}} Q${{cx}},${{cy}} ${{sx1}},${{sy1}} Z`;
const isHighlighted = highlightNode === -1 || highlightNode === l.source || highlightNode === l.target;
const opacity = highlightNode === -1 ? 0.35 : (isHighlighted ? 0.6 : 0.04);
const reverseVal = flowLookup[l.target + '::' + l.source] || 0;
svg += `<path class="chord" d="${{chordD}}" fill="${{sa.color}}" opacity="${{opacity}}"
data-src="${{l.sourceLabel}}" data-tgt="${{l.targetLabel}}" data-val="${{l.value}}"
data-si="${{l.source}}" data-ti="${{l.target}}" data-rev="${{reverseVal}}"
onmouseenter="hoverChord(event, this)" onmouseleave="unhover()"/>`;
}});
arcs.forEach((a, i) => {{
const isHighlighted = highlightNode === -1 || highlightNode === a.idx;
const opacity = highlightNode === -1 ? 1 : (isHighlighted ? 1 : 0.2);
svg += `<path d="${{arcPath(a.startAngle, a.endAngle, innerR, outerR)}}"
fill="${{a.color}}" opacity="${{opacity}}" style="cursor:pointer"
data-idx="${{a.idx}}"
onmouseenter="hoverNode(event, ${{a.idx}}, '${{a.label.replace(/'/g, "\\\\'")}}',${{a.total}})"
onmouseleave="unhover()"
/>`;
const mid = a.midAngle;
const lx = cx + Math.cos(mid) * labelR;
const ly = cy + Math.sin(mid) * labelR;
const deg = (mid * 180 / Math.PI);
const flip = deg > 90 || deg < -90;
const textRotate = flip ? deg + 180 : deg;
const anchor = flip ? 'end' : 'start';
svg += `<text x="${{lx}}" y="${{ly}}"
text-anchor="${{anchor}}" dominant-baseline="central"
transform="rotate(${{textRotate}}, ${{lx}}, ${{ly}})"
font-size="12px"
font-weight="500" fill="${{isHighlighted || highlightNode === -1 ? '#e2e4e9' : '#333'}}"
opacity="${{opacity}}"
style="pointer-events:none">${{a.label}}</text>`;
}});
svg += '</svg>';
document.getElementById('chord').outerHTML = svg;
}}
const tooltip = document.getElementById('tooltip');
function hoverChord(e, el) {{
const src = el.getAttribute('data-src');
const tgt = el.getAttribute('data-tgt');
const val = parseInt(el.getAttribute('data-val'));
const rev = parseInt(el.getAttribute('data-rev') || '0');
highlightNode = -1;
let html = `<div style="margin-bottom:6px;font-size:11px;color:#6b7084;text-transform:uppercase;letter-spacing:0.5px">Bidirectional Flow</div>`;
html += `<div style="margin-bottom:4px"><span class="tt-from">${{src}}</span> <span class="tt-arrow">→</span> <span class="tt-to">${{tgt}}</span></div>`;
html += `<div class="tt-val">${{val.toLocaleString()}} links</div>`;
if (rev > 0) {{
html += `<div style="margin-top:8px;padding-top:8px;border-top:1px solid #1e2230"><span class="tt-to">${{tgt}}</span> <span class="tt-arrow">→</span> <span class="tt-from">${{src}}</span></div>`;
html += `<div class="tt-val">${{rev.toLocaleString()}} links</div>`;
}} else {{
html += `<div style="margin-top:8px;padding-top:8px;border-top:1px solid #1e2230;color:#6b7084"><span>${{tgt}} → ${{src}}</span></div>`;
html += `<div style="color:#6b7084">No reverse links</div>`;
}}
tooltip.innerHTML = html;
tooltip.classList.add('show');
posTooltip(e);
const si = parseInt(el.getAttribute('data-si'));
const ti = parseInt(el.getAttribute('data-ti'));
document.querySelectorAll('.chord').forEach(c => {{
const cs = parseInt(c.getAttribute('data-si'));
const ct = parseInt(c.getAttribute('data-ti'));
const isThis = (cs === si && ct === ti);
const isReverse = (cs === ti && ct === si);
c.setAttribute('opacity', (isThis || isReverse) ? '0.7' : '0.04');
}});
}}
function hoverNode(e, idx, label, total) {{
highlightNode = idx;
const outgoing = {{}};
const incoming = {{}};
RAW.links.forEach(l => {{
if (l.value <= minLinks) return;
if (hideSelf && l.source === l.target) return;
if (l.source === idx) outgoing[l.targetLabel] = (outgoing[l.targetLabel] || 0) + l.value;
if (l.target === idx) incoming[l.sourceLabel] = (incoming[l.sourceLabel] || 0) + l.value;
}});
const outTotal = Object.values(outgoing).reduce((a, b) => a + b, 0);
const inTotal = Object.values(incoming).reduce((a, b) => a + b, 0);
let html = `<div style="font-size:16px;font-weight:700;margin-bottom:8px" class="tt-from">${{label}}</div>`;
html += `<div style="display:flex;gap:20px">`;
html += `<div><div style="color:#6b7084;font-size:11px;text-transform:uppercase">Outgoing</div><div class="tt-val">${{outTotal.toLocaleString()}}</div></div>`;
html += `<div><div style="color:#6b7084;font-size:11px;text-transform:uppercase">Incoming</div><div class="tt-val">${{inTotal.toLocaleString()}}</div></div>`;
html += `</div>`;
const topOut = Object.entries(outgoing).sort((a,b) => b[1]-a[1]).slice(0, 5);
const topIn = Object.entries(incoming).sort((a,b) => b[1]-a[1]).slice(0, 5);
if (topOut.length) {{
html += `<div style="margin-top:8px;padding-top:8px;border-top:1px solid #1e2230;font-size:11px;color:#6b7084">TOP OUTGOING</div>`;
topOut.forEach(([name, count]) => {{
html += `<div style="font-size:12px">→ ${{name}}: <span style="color:#6c72cb">${{count.toLocaleString()}}</span></div>`;
}});
}}
if (topIn.length) {{
html += `<div style="margin-top:6px;font-size:11px;color:#6b7084">TOP INCOMING</div>`;
topIn.forEach(([name, count]) => {{
html += `<div style="font-size:12px">← ${{name}}: <span style="color:#cb69c1">${{count.toLocaleString()}}</span></div>`;
}});
}}
tooltip.innerHTML = html;
tooltip.classList.add('show');
posTooltip(e);
render();
}}
function unhover() {{
highlightNode = -1;
tooltip.classList.remove('show');
render();
}}
document.addEventListener('mousemove', posTooltip);
function posTooltip(e) {{
if (!tooltip.classList.contains('show')) return;
tooltip.style.left = (e.clientX + 16) + 'px';
tooltip.style.top = (e.clientY - 12) + 'px';
}}
const slider = document.getElementById('minSlider');
const valSpan = document.getElementById('minVal');
slider.addEventListener('input', () => {{
minLinks = parseInt(slider.value);
valSpan.textContent = minLinks.toLocaleString();
render();
}});
document.getElementById('toggleSelf').addEventListener('click', function() {{
hideSelf = !hideSelf;
this.textContent = hideSelf ? 'Show self-links' : 'Hide self-links';
render();
}});
document.getElementById('resetBtn').addEventListener('click', () => {{
hideSelf = false;
minLinks = 0;
searchTerm = '';
slider.value = 0;
valSpan.textContent = '0';
document.getElementById('search').value = '';
document.getElementById('toggleSelf').textContent = 'Hide self-links';
render();
}});
document.getElementById('search').addEventListener('input', (e) => {{
searchTerm = e.target.value;
render();
}});
const maxLinkVal = Math.max(...RAW.links.map(l => l.value), 100);
slider.max = Math.min(maxLinkVal, 10000);
render();
window.addEventListener('resize', () => {{ highlightNode = -1; render(); }});</script> </body>
</html>"""
return html
# ─────────────────────────────────────────────────────────────────────
# STREAMLIT APP
# ─────────────────────────────────────────────────────────────────────
def main():
st.set_page_config(
page_title="Internal Link Sankey Builder",
page_icon="🔗",
layout="wide",
)
st.title("Internal Link Sankey Builder")
st.caption(
"Upload a CSV with internal links, define regex rules to cluster URLs, "
"and visualize link flow as an interactive Sankey."
)
# ── Sidebar: File upload & column config ──
with st.sidebar:
st.header("1. Upload CSV")
uploaded_file = st.file_uploader(
"Internal linking CSV", type=["csv", "tsv", "txt"]
)
delimiter = st.selectbox("Delimiter", [",", "\t", ";", "|"], index=0)
if uploaded_file is not None:
file_content = uploaded_file.getvalue().decode("utf-8-sig", errors="replace")
reader = csv.DictReader(StringIO(file_content), delimiter=delimiter)
columns = reader.fieldnames or []
if not columns:
st.error("No columns found in CSV. Check delimiter.")
return
st.header("2. Select Columns")
source_col = st.selectbox("Source URL column", columns, index=0)
target_idx = min(1, len(columns) - 1)
target_col = st.selectbox(
"Target URL column", columns, index=target_idx
)
st.header("3. Options")
exclude_unclustered = st.checkbox(
"Exclude unclustered URLs", value=False,
help="Hide links where either source or target doesn't match any rule.",
)
min_links = st.number_input(
"Min links to show a flow", min_value=0, value=0, step=1
)
# ── Main area: Rules editor ──
st.header("URL Clustering Rules")
st.markdown(
"Define regex patterns to match against URLs. "
"Each URL is assigned to the **first matching** rule's cluster. "
"Full regex supported — `|` for OR, `^`/`$` for exact match, `\\.` for literal dot."
)
col_pattern, col_cluster, col_action = st.columns([3, 2, 1])
with col_pattern:
st.markdown("**URL pattern (regex)**")
with col_cluster:
st.markdown("**Cluster name**")
with col_action:
st.markdown("**Action**")
rules_to_remove = []
for i, rule in enumerate(st.session_state.rules):
col_p, col_c, col_a = st.columns([3, 2, 1])
with col_p:
st.session_state.rules[i]["pattern"] = st.text_input(
f"pattern_{i}",
value=rule["pattern"],
label_visibility="collapsed",
placeholder="e.g. /blog/|/news/ or ^https://example\\.com/$",
key=f"pat_{i}",
)
with col_c:
st.session_state.rules[i]["cluster"] = st.text_input(
f"cluster_{i}",
value=rule["cluster"],
label_visibility="collapsed",
placeholder="e.g. Technical SEO",
key=f"cls_{i}",
)
with col_a:
if st.button("Remove", key=f"rm_{i}", use_container_width=True):
rules_to_remove.append(i)
if rules_to_remove:
for idx in sorted(rules_to_remove, reverse=True):
st.session_state.rules.pop(idx)
st.rerun()
col_add, col_clear, _ = st.columns([1, 1, 3])
with col_add:
if st.button("+ Add rule", use_container_width=True):
st.session_state.rules.append({"pattern": "", "cluster": ""})
st.rerun()
with col_clear:
if st.button("Clear all", use_container_width=True):
st.session_state.rules = [{"pattern": "", "cluster": ""}]
st.rerun()
# ── Generate ──
st.divider()
if uploaded_file is None:
st.info("Upload a CSV in the sidebar to get started.")
return
valid_rules = [
r
for r in st.session_state.rules
if r["pattern"].strip() and r["cluster"].strip()
]
if not valid_rules:
st.warning("Add at least one clustering rule with both a pattern and a cluster name.")
return
if st.button("Generate Sankey", type="primary", use_container_width=True):
compiled = compile_rules(valid_rules)
if not compiled:
st.error("No valid rules to apply.")
return
with st.spinner("Processing CSV and building Sankey..."):
flow, stats = process_csv(
file_content,
source_col,
target_col,
compiled,
exclude_unclustered,
delimiter,
)
if not flow:
st.error("No link flows found. Check your columns and rules.")
return
sankey_data = prepare_sankey_data(flow, min_links=min_links)
html = generate_html(sankey_data)
st.session_state.sankey_html = html
st.session_state.sankey_stats = stats
st.session_state.sankey_flow = flow
total_links = sum(flow.values())
clusters_found = set()
for src, tgt in flow:
clusters_found.add(src)
clusters_found.add(tgt)
st.success(
f"Done — {total_links:,} links across {len(clusters_found)} clusters, "
f"{len(flow)} unique flows."
)
# ── Display & Download ──
if st.session_state.sankey_html:
st.subheader("Sankey Diagram")
st.components.v1.html(st.session_state.sankey_html, height=700, scrolling=False)
st.download_button(
label="Download Sankey as HTML",
data=st.session_state.sankey_html,
file_name="cluster_sankey.html",
mime="text/html",
use_container_width=True,
)
if st.session_state.get("sankey_stats"):
stats = st.session_state.sankey_stats
with st.expander("Debug: Processing Summary", expanded=False):
col1, col2, col3, col4 = st.columns(4)
col1.metric("Total CSV rows", f"{stats['total_rows']:,}")
col2.metric("Counted (used)", f"{stats['counted']:,}")
col3.metric("Skipped (empty src/tgt)", f"{stats['skipped_empty']:,}")
col4.metric("Skipped (unclustered)", f"{stats['skipped_unclustered']:,}")
st.markdown("**URL appearances per cluster** (source + target side counted separately):")
cluster_counts = stats["cluster_url_counts"]
for cluster in sorted(cluster_counts, key=cluster_counts.get, reverse=True):
st.text(f" {cluster}: {cluster_counts[cluster]:,}")
st.markdown("**Flow breakdown** (source cluster -> target cluster = count):")
flow = st.session_state.get("sankey_flow", {})
for (src, tgt), count in sorted(flow.items(), key=lambda x: x[1], reverse=True):
st.text(f" {src} -> {tgt} = {count:,}")
if __name__ == "__main__":
main()
You can also download sankey chart visualisation as an HTML file.
This visualization can be extremely useful to visualize flow of internal linking between the content groups.

In a bidirectional way it even quantifies the no of links.

Kunjal Chawhan founder of Decode Digital Market, a Digital Marketer by profession, and a Digital Marketing Niche Blogger by passion, here to share my knowledge