

Summarize this post with:
Ever wondered how cool it would be if you could visualize large News Site URLs (Millions of URLs) in Topical Clusters to observe the biggest clusters they have?
Data Visualization can contain a treasure trove of data.
Guess what? it can be done & no you do not need to crawl the millions of URLs spending days it can be done within 10-15 minutes.
Shocking isn’t it?
Thanks to Advertools Python Library, this is the very Library that makes it so easy for you to execute this.
I will quickly summarize how I managed to achieve this for a popular News site in India called Hindustan Times & visualized millions of URLs in topical clusters.
The advertools library has a function for sitemaps wherein you can easily extract the sitemap URLs & visualize in the table and then you can use the same table data frame to visualize the URLs in Topical Clusters.
Since the Hindustan Times website follows a silo structure instead of a flat structure that is what made the clustering process so much simpler.
I let the Python Script treat the subfolder as a cluster.
Just give an example
This URL will belong to Cricket Cluster because the subfolder is Cricket.
Without Further Ado, here is the Python Script & Visualization I created
Pro tip: It’s best to use Google Collab as an IDE instead of Replit because Google Colab would create Treemap Visualization within Google Colab itself.
Step 1: Install the necessary requirements
!pip install advertools
!pip install requests
!pip install plotly
Step 2: Crawl all the Sitemaps via Advertools Library & Store them in the table visualization
import advertools as adv
import pandas as pd
# List of sitemap URLs
sitemap_urls = [
'https://www.hindustantimes.com/sitemap/news.xml',
'https://www.hindustantimes.com/sitemap/section.xml',
'https://www.hindustantimes.com/sitemap/index.xml'
]
# Create an empty DataFrame to store the combined results
combined_sitemaps = pd.DataFrame()
# Iterate through each sitemap URL and append the data to the combined DataFrame
for url in sitemap_urls:
sitemap_data = adv.sitemap_to_df(url)
combined_sitemaps = combined_sitemaps.append(sitemap_data)
combined_sitemaps.head()
In the above code block, you can see how at once we have crawled not one but several sitemaps.
And one of those sitemaps is nested containing hundreds of sitemaps.
URLs under every sitemap is going to be fetched & added to the table.

Once you execute the code block, you can see the sitemap URL data in the table like this.
Step 3: Visualize Millions of Sitemap URLs in Topical Clusters
import pandas as pd
import plotly.express as px
# Assuming you already have the combined_sitemaps DataFrame
# Extract subfolder names
combined_sitemaps['subfolder'] = combined_sitemaps['loc'].str.extract(r'//www\.hindustantimes\.com/([^/]+)/')
# Create a DataFrame with cluster counts
cluster_counts = combined_sitemaps['subfolder'].value_counts().reset_index()
cluster_counts.columns = ['Cluster', 'Count']
# Plotting the Treemap with Plotly
fig = px.treemap(cluster_counts, path=['Cluster'], values='Count', title='News URL Cluster Distribution')
fig.show()
Here the Python Script is instructed to treat the folder after the root domain as a topical cluster. Hence you will see this line in the script.
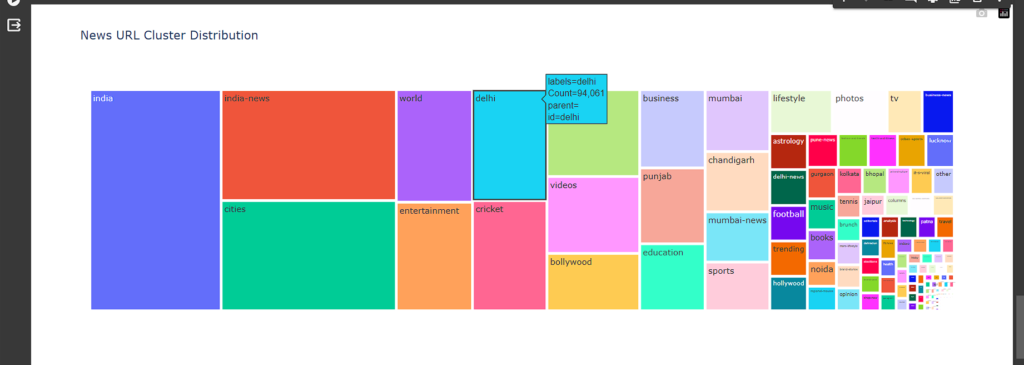
Tada! 🎉
That’s just about it. In the above screenshot, you can see how we are able to visualize millions of URLs in Clustered Topically.
As you hover over the clusters you can see the number of URLs each cluster has.
Like how you can see that Delhi as a cluster has 94,061 URLs.
I think this is a super handy script as it takes less than 15 minutes to visualize clusters of large sites containing millions of URLs.
The only caveat is that for clustering this script relies on subfolder structure which most news sites have.
But if we are doing this for a large site that uses flat architecture or doesn’t use silo structure then in that case for clustering a logic will be needed to be developed.

Kunjal Chawhan founder of Decode Digital Market, a Digital Marketer by profession, and a Digital Marketing Niche Blogger by passion, here to share my knowledge