

Summarize this post with:
Last updated on April 6th, 2021 at 06:39 am
It is argued that the industry of SEO is nearly 20 years old. (source)
Even after all these years, there appears to be an enormous amount of chaos around the use of these two tools in search engine optimization.
One is Noindex Meta Tag and another is Robots.txt
Do you also have this same question in mind?
Sit tight, because in this post we will decode what they are and what are their disparate purposes.
This post isn’t about which one is better because this isn’t remotely a competition. The tools are different.
What is a Noindex Meta Tag?
A Noindex Meta Tag is a directive that you can place at the head section of a page. It looks like this →
<meta name="robots" content="noindex">Adding this directive you can prevent the indexing of the said page. It is important to understand here that the noindex meta tag doesn’t affect the crawling of the page; it affects the indexing.
What is Google's Opinion about NoIndexing?
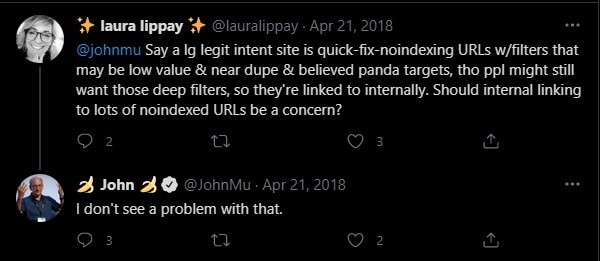
Could internally linking deep noindex pages cause any issue?
NO
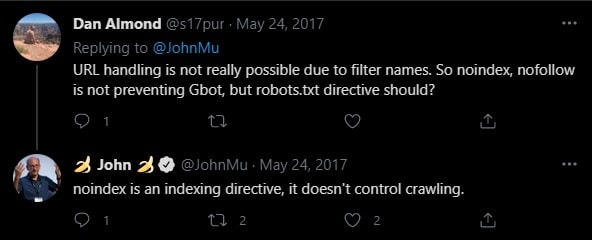
Does NoIndexing control Google Bot Crawling?
NO
How should large site owners handle the blocking of URLs?

CONRADICTION: Google on the other hand also suggests NoIndexing instead of blocking in the Robots.txt

What is Robots.txt?
A robots.txt file is a text file that carries directives that state which files are search engine bots allowed to crawl and which files they aren’t allowed to crawl and access.
The search engine bots are respectful of these directives and accordingly obeys.
A Robots.txt file looks like this →
User-agent: * Disallow:The above robots.txt file is allowing search engine bots to access every file on the website.
Let’s say you got an E-Commerce SEO Project and you have discovered 10,000 junk pages that are doing you no good; now if you apply noindex meta tag in these pages then what happens is that Google will crawl these pages and discover the presence of noindex meta tag after which it will drop the page out of the index.
This however might not be the right thing to do; because it’s like wasting Google Bot crawl budget for one time for dozens of pages.
I mean in the given example it’s the right thing to do.
In the same e-commerce website, let’s assume that the pages like /thank-you/, /subscription-confirmed/, /cart/, /login/ are also on the indexed then the right thing here to do would be to not even waste a tiny bit of Google’s crawl budget and have these pages disallowed in Robots.txt right away.
Because you don’t even want the search engine bots to crawl these pages. Here the motto isn’t just to not have these indexed but the motto here more importantly is to not even have them crawled.
Wrapping it up!
Robots.txt file is used to control search engine bot crawling whereas Noindex Meta Robots Tag is used to control the indexing
Google Resources:

Kunjal Chawhan founder of Decode Digital Market, a Digital Marketer by profession, and a Digital Marketing Niche Blogger by passion, here to share my knowledge